不止生成:迈向更好的分子几何表征
介绍 LENSEs:通过表征精炼、分子语义损失与生成器内部表征对齐,提升表示条件分子生成与分子几何表征质量。
本文同步自知乎:不止生成:迈向更好的分子几何表征。
Paper: arXiv:2605.07693
这是我从去年年底开始一直在推进的一项工作,现在终于 make public 啦!
从最初的想法、实验设计,到一轮轮修改与完善,这篇文章经历了很长的打磨过程。非常感谢 MuLab@PKU 的学长们 Zian 和 Cai 长久以来的帮助,也感谢 ByteDance mentor Qiaojing 持续的跟进与支持。很高兴能够把这项工作正式呈现给大家,也希望它能为分子生成与分子表征学习提供一些新的视角。
在 3D 分子生成任务中,我们通常关心一个直接的问题:模型能否生成合理、稳定、具有物理意义的分子结构。
这个问题看似主要取决于生成器本身——例如扩散模型是否足够强,等变结构是否设计得足够好,去噪轨迹是否足够稳定。但在表示条件生成(representation-conditioned generation)的范式下,还有一个更隐蔽、却同样关键的问题:模型究竟依赖怎样的分子表征来进行生成?
如果条件表征本身是粗糙的、非光滑的,或者没有与生成目标充分对齐,那么即使下游生成器很强,也可能只能在一个并不理想的语义空间中工作。换句话说,生成质量的上限,不仅由 generator 决定,也由 conditioning representation 的质量决定。
这正是我们提出 LENSEs (Latent Enhancement for Non-smooth Structural Encodings) 的出发点。
从“生成模型”到“表征质量”
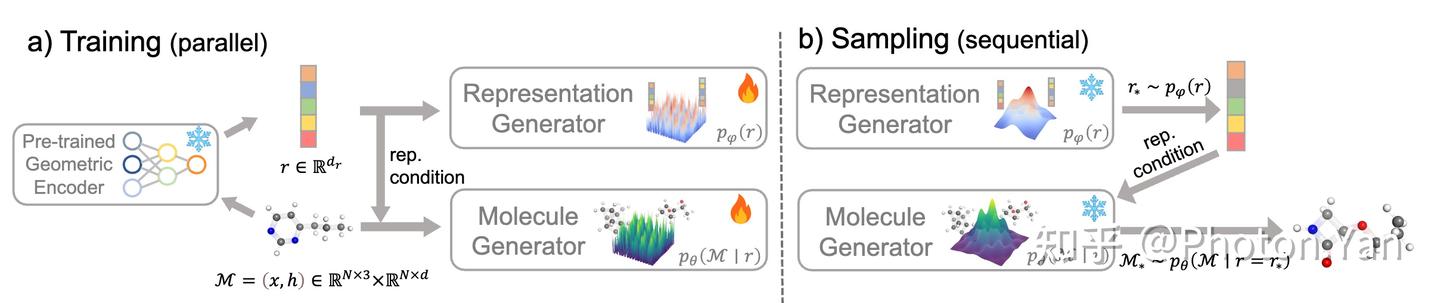
近年来,几何表示条件分子生成(Representation-conditioned Molecule Generation)逐渐成为一种有效的建模范式。它将 3D 分子生成拆分为两个阶段:首先得到一个包含分子语义信息的表示,然后以该表示为条件生成具体的三维分子结构。
GeoRCG (Li Z, Zhou C, Wang X, et al. Geometric representation condition improves equivariant molecule generation[J]. arXiv preprint arXiv:2410.03655, 2024)
这样的设计有一个清晰的优势:它把“理解分子”和“生成结构”解耦开来。预训练分子编码器可以从大量分子数据中学习化学与几何信息,而生成器则专注于在给定条件下恢复或生成合理结构。
然而,这种范式也带来了一个容易被忽视的瓶颈:预训练编码器学到的表征,并不一定天然适合生成任务。
一个编码器的最终层表示可能对某些判别任务很有用,却未必足够光滑、可插值,也未必与生成器的内部动力学保持一致。对于生成模型而言,条件空间不仅要“有语义”,还要“可生成”:相近的表示应当对应相近的分子结构,表示空间中的变化应当尽可能连续、稳定,并且能够被生成器有效利用。
如果这一点不成立,生成器就像是在一张皱折的地图上行走:地图里确实标注了目的地,但路径并不平滑,局部变化可能突然跳转,语义距离也未必对应结构距离。结果是,生成器虽然被赋予了条件信息,却很难稳定地将这些信息转化为高质量分子。
因此,我们的核心观点是:
要提升条件分子生成,不能只改进生成器本身,也必须重新审视并优化用于条件生成的分子表征。
一个关键观察:不同编码层包含不同化学语义
在分析预训练分子编码器时,我们发现了一个有趣现象:编码器的浅层表征在官能团分类任务中往往具有更强的可分性。 具体而言,我们将分子输入冻结的预训练分子编码器,并分别提取不同编码层输出的节点级与图级表示。随后,我们构造了一组官能团分类任务,将每个分子是否包含特定官能团作为监督信号,在不同层的表示之上训练轻量级分类器。为了避免分类器本身过强而掩盖表征差异,我们仅使用简单的线性探针或浅层 MLP,并保持编码器参数完全冻结。
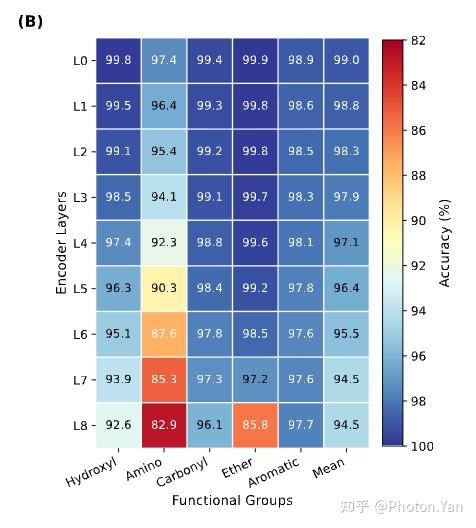
Frad 上各层表征的线性探针(Linear Probing)实验对六种官能团判别准确率热力图
这样的实验设置本质上是在问一个问题:如果不允许编码器继续学习,仅凭某一层已经形成的表示,模型能否直接区分不同官能团模式?结果显示,浅层表示在若干官能团识别任务上反而取得了更好的分类性能,说明这些层中保留了更清晰的局部化学结构信息。
这说明分子编码器的不同层级并不是简单地“越深越好”。浅层表示可能更敏感于局部原子环境、官能团模式与短程结构;深层表示则更倾向于整合全局构象与整体语义。不同层之间携带的是互补信息,而不是单一方向上的质量递增。
这对表示条件生成非常重要。因为分子生成不仅需要全局结构信息,也需要局部化学模式的精确约束。一个高质量的条件表征,不应只来自编码器最后一层,而应当能够综合不同层级的化学语义。
基于这一观察,LENSEs 不直接使用编码器最后一层的单一表示,而是从多个编码层中提取多层次分子表征,并通过可学习的 layer pooling 自适应地融合这些信息。这样,模型可以根据生成任务的需要,从浅层的局部语义和深层的全局语义中共同获益。
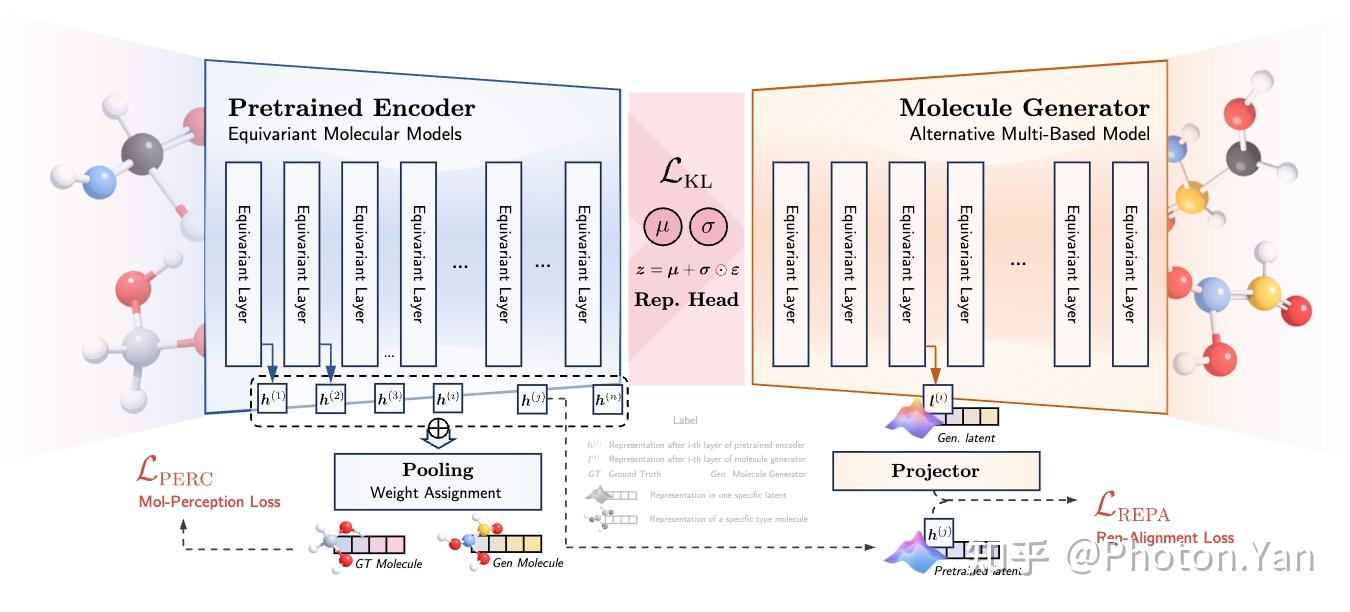
LENSEs:让表征更适合生成
LENSEs 的目标并不是推翻已有的表示条件生成范式,而是进一步释放其中“分子表征”的潜力。我们希望把预训练编码器产生的表示,从一个静态的输入条件,转化为一个可以被生成任务主动优化、对齐和利用的中间空间。
为此,LENSEs 引入了三个互补机制。
1. Representation Head:重塑条件表征空间
首先,LENSEs 在冻结的预训练分子编码器之上引入一个 representation head。它从多个编码层中抽取分子表示,并通过可学习的 layer pooling 进行融合,经一个由重参数化技巧正则的输出头,得到更适合生成任务的条件表示。
这个设计的关键在于:我们不再假设预训练编码器的原始输出就是最优条件。相反,我们允许模型在生成训练过程中重新组织这些表征,使其变得更光滑、更紧凑,也更贴近生成器真正需要的信息。
在实现上,representation head 可以被看作一个轻量的表征精炼模块。它保留了预训练编码器中已有的化学知识,同时通过生成任务的反馈调整条件空间的结构。这样,生成器接收到的不再是一个未经处理的 encoder embedding,而是一个经过任务适配的、更加 generation-friendly 的分子表示。
2. Molecule Perceptual Loss:在语义空间中约束生成结果
仅仅优化坐标误差或传统生成损失,并不一定能保证生成分子在语义层面与目标分子接近。两个分子在局部坐标上可能看似相似,但在更高层的化学语义上存在差异;反过来,一些几何扰动可能并不严重影响整体分子语义。
因此,LENSEs 引入分子语义损失(molecule perceptual loss)。它利用冻结的预训练分子编码器,将生成分子和真实分子映射到语义表征空间中,并在该空间内度量二者的差异。
这种做法类似于计算机视觉中的 perceptual loss:我们不只在像素层面比较两张图像,而是在深层特征空间中比较它们是否表达了相同内容。对于分子而言,我们也希望生成器不仅复现坐标,更要复现分子背后的结构语义与化学模式。
通过这种方式,生成器获得了来自预训练编码器的语义监督,能够更好地学习“什么样的结构变化是真正重要的”。
3. REPA Loss:对齐生成器内部表征与编码器语义
第三个机制是 node-level representation alignment,也就是 REPA loss。
在表示条件生成中,即使输入条件包含了丰富语义,生成器内部是否真正利用这些信息仍然是一个问题。生成器的隐藏状态可能与编码器表征存在语义鸿沟:条件信息被输入了模型,但没有被充分吸收进生成过程的中间动力学。
REPA loss 的作用,就是显式地缩小这个鸿沟。它将生成器内部的节点级隐藏表示投影到编码器表征空间,并通过相似性约束,使生成器的中间特征与预训练编码器捕获的分子语义保持一致。
这样,LENSEs 不仅在输入端改善条件表示,也在生成过程内部推动语义对齐。生成器不再只是“接收”一个表征,而是在自己的隐藏层中逐步建立与该表征一致的结构理解。
为什么这三部分是互补的?
LENSEs 的整体结构图
LENSEs 的三个模块分别作用在不同层面。
Representation head 作用于条件空间本身,让输入给生成器的分子表示更加平滑、紧凑和任务适配;molecule perceptual loss 作用于生成结果,使输出分子在语义空间中接近真实分子;REPA loss 则作用于生成器内部过程,使模型隐藏状态与编码器语义发生对齐。
换句话说,LENSEs 不是只在一个位置打补丁,而是从“条件表示—生成结果—内部动力学”三个层面共同提升 representation-conditioned generation 的质量。
这也对应了我们对问题本质的理解:如果条件分子生成依赖表征,那么表征就不应该只是一个固定的外部输入,而应当贯穿整个生成过程。
实验结果:生成能力与表征质量同步提升
LENSEs 的实验并不只回答“模型能否生成更好的分子”,也进一步追问:在提升分子生成能力的过程中,模型是否真的学到了更好的分子表征?
首先,在 GEOM-DRUG 等具有挑战性的分子生成任务上,LENSEs 展现出稳定的生成性能提升。经过表征精炼与语义对齐后,模型能够生成更高比例的有效分子,并保持甚至进一步提升生成分子的稳定性与物理合理性。
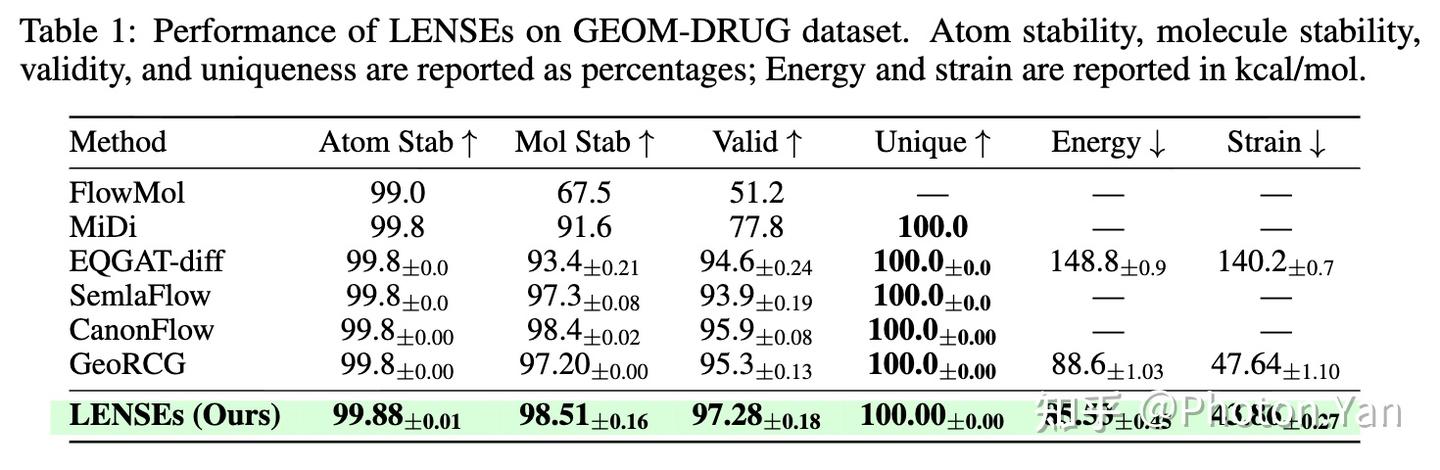
GEOM-DRUG 上的生成实验结果
例如,在 GEOM-DRUG 上,LENSEs 达到了 97.28% 的 validity,显示出相较于 GeoRCG、CanonFlow 等强基线的有力改进。同时,模型在 atom stability、molecule stability、energy validity、opt-RMSD 等指标上也达到了最优,说明提升表征质量并不是以牺牲结构稳定性为代价,而是能够真正转化为更可靠的生成。
一个真正「好」的分子表征,不应仅仅是生成器专属的“附属品”,而必须具备跨任务的泛化能力。为了验证 LENSEs 的 representation head 学到的表征是否真的足够优秀,我们在生成任务之外,引入了一个经典的下游评估:冻结训练好的表征模块,仅在末端接入一个轻量级输出头(类似 linear probing 的设置),直接进行 QM9 分子性质预测任务。
这里的核心逻辑非常直白:如果一个表征空间的质量足够高,那么即便只用极简的浅层预测头,也能轻松从中“读”出分子的各种物理化学性质。也就是说,高质量的表征不该依赖下游复杂模型的反复找补,而应直接将目标性质在隐空间中理清,使其更加线性可分与可预测。
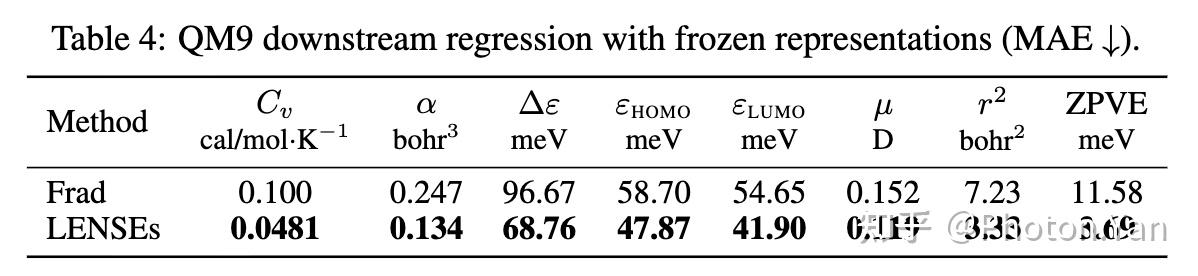
QM9 上的性质预测探针测试结果
结果如我们所料且令人振奋:相比直接使用基线编码器的提取特征,经过 LENSEs 表征头精炼后的表示,在 QM9 的各项性质预测上均取得了显著提升,回归误差(MAE)全面下降。这有力地证明了,LENSEs 并非仅仅为了讨好生成器而挤出了一套特化编码;相反,它确实从根本上改善了分子表示本身,让下游任务能够以更简单的形式高效读取化学知识。
这一性能飞跃的背后,有着坚实的表征空间几何证据支撑。我们发现,原始分子编码器往往饱受非光滑性与维度塌缩的困扰。而经过 LENSEs 精炼后,不仅条件空间的局部经验利普西斯常数实现了大幅下降(例如在 GEOM-DRUG 数据集上降低了 4.6 倍,空间变得更为平滑),其表征的有效秩(Effective Rank)也得到显著提升,被压缩的信息维度被重新打开。这种几何性质上的改善,印证了下游性质预测中展现出的强可读性。
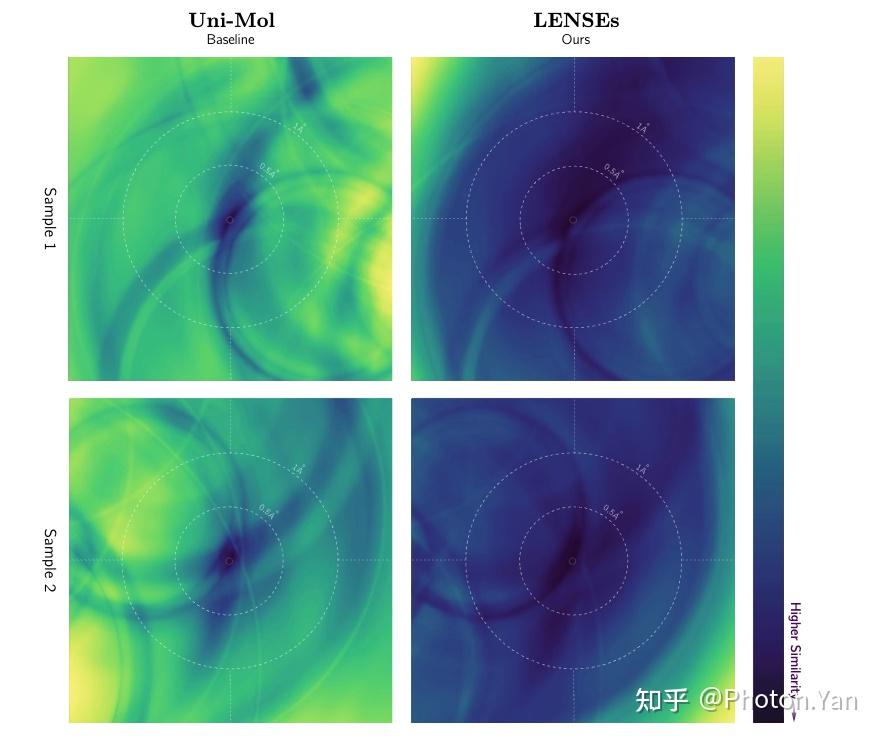
Baseline 和 LENSEs 的表征空间平滑性示意图,颜色越深越平滑。
至此,LENSEs 的实验揭示了一个更具启发性的深层结论:生成任务与表征学习绝非单向关系。 更好的表征固然是高质量生成的基石;但与此同时,以语义对齐和生成为目标的训练(Generative Training),也能反哺并孕育出更加平滑、丰富且可迁移的分子表征。生成任务,不只是表征的使用者,同样可以成为卓越的表征塑造者。
结语
LENSEs 的意义不在于提出一个更复杂的生成器,而在于重新强调一个常被低估的事实:在表示条件生成中,预训练编码器并不只是一个提供固定 condition 的工具,它本身蕴含着尚未被充分捕捉和发挥的分子结构信息。
已有的分子编码器已经从大规模数据中学习到了丰富的化学与几何知识,但这些知识并不会自动以最适合生成任务的形式呈现出来。最后一层表征未必包含全部有用信息,原始表征空间也未必足够平滑、稳定或与生成器内部动力学对齐。因此,简单地“拿来一个 encoder embedding 作为条件”并不能充分释放预训练编码器的能力。
LENSEs 的核心作用,正是在预训练编码器与生成模型之间建立一套更有效的连接机制。通过多层表示聚合,模型能够更充分地捕捉编码器不同层级中的局部与全局化学语义;通过 representation head,原始表征被进一步精炼为更适合生成的条件空间;通过 molecule perceptual loss 和 REPA loss,预训练编码器中的语义信息不仅进入输入条件,也进一步参与到生成结果与生成过程的约束之中。
因此,LENSEs 本质上是在回答一个重要问题:如何让预训练分子编码器中已经学到的信息真正服务于分子生成?
更进一步,LENSEs 的实验结果也暗示了一种潜在的分子生成式预训练范式。 我们发现,在提升生成能力的同时,经过生成任务训练的 representation head 也能产生更高质量的分子表征;这些表征在 QM9 target prediction 的 linear probing 设置中更容易被简单输出头读取,说明生成训练并不只是消耗表征,而可能反过来塑造表征。
这意味着,分子生成任务可以不仅被看作 downstream generation,也可以被看作一种 representation learning signal:通过要求模型从表征生成合理的三维结构,模型被迫学习哪些化学语义是真正有用的,哪些几何变化是稳定且可解释的,哪些结构信息应当被保留下来并组织进更平滑的表示空间。
从这个角度看,LENSEs 指向的不只是一个更强的条件分子生成模型,而是一种新的可能性:以生成任务反哺表征学习,用生成式预训练获得更好的分子几何表征。
未来,分子领域的预训练或许不应只依赖掩码预测、对比学习或性质预测等判别式目标。生成式目标同样可以成为理解分子结构的重要途径。因为当模型被要求生成一个物理合理、化学稳定的三维分子时,它学习到的并不只是如何采样坐标,而是如何把分子的局部结构、全局构象与化学语义组织成一个可用、可读、可生成的表示空间。
这也是 LENSEs 希望传达的核心观点:更好的生成,来自更充分的表征利用;而更好的表征,也可能在生成过程中被重新塑造。